存储原理
数据页
MySQL 从磁盘装载数据到内存时,是以页为单位的,一次装载一个或多个 Page
下图就是 MySQL 内存里面一页数据的结构(一个页的大小固定为16KB)
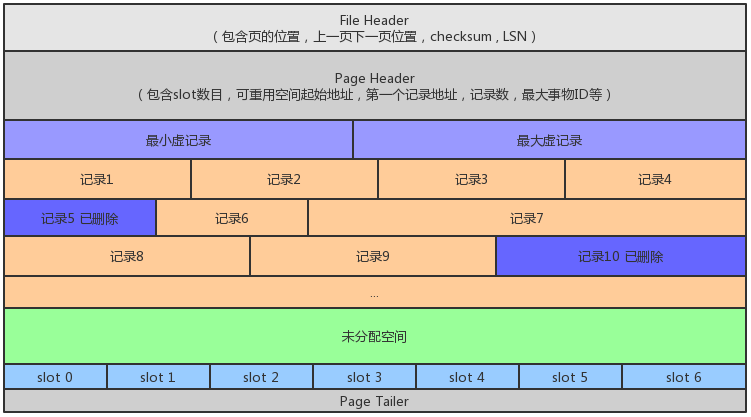
- 页头:记录页面的控制信息,共 56 字节,包括相邻页面指针(页与页会组成一个双向链表)、页面空间使用情况等
- 虚记录:其本身不存储数据,它记录了这一页存储的数据的范围,这样就能知道某数据有没有落在这一页
其中,最大虚记录比页内最大主键还大,最小虚记录比页内最小主键还小 - 记录堆:行记录存储区,分为有效记录和已删除记录
- 自由空间链表:已删除记录组成的链表,在写数据时会优先利用这部分空间,这样能够减少页面的空洞
- 未分配空间:页面未使用的存储空间
- Slot区:在页内查找记录时用的,通过它能够做到近似二分查找,提高查询效率
- 页尾:页面的最后部分,是一个 8 个字节的校验位,主要存储页面的校验信息(能知道页面数据有没有发生错误)
插入策略
先尝试往页中的自由空间链表里面写
当自由空间链表里面没有地方的时候,才会往未分配空间里面写
这样就可以把页面的空洞最大化的利用起来
顺序保证
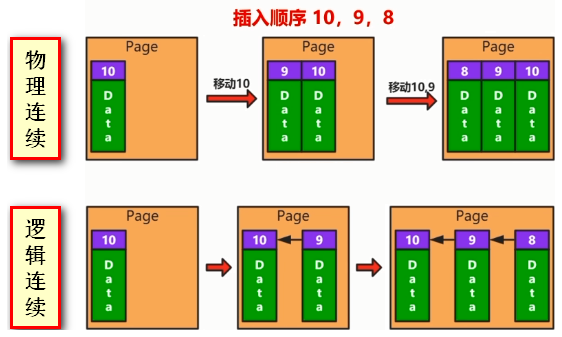
如上图所示,依次插入主键为 10、9、8 的数据
假设通过物理连续来保证顺序(见上图的上半部分),那插入 9 时就得移动 10,插入 8 的时候就得移动 10 和 9
但若通过逻辑连续来保证顺序(见上图的下半部分),那插入 9 时不用移动 10,在 9 上面用一个指针指向 10 即可
由于频繁移动数据的性能开销是比较大的,所以 MySQL 采用的是逻辑连续来保证顺序
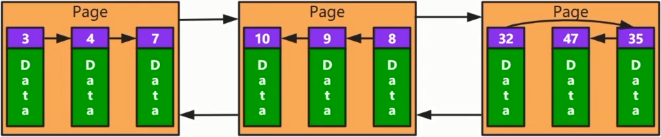
也就是说,页内是单向链表,而页间则采用的是双向链表(每个页头都有指针指向相邻的页)
如下图所示:
页内查询
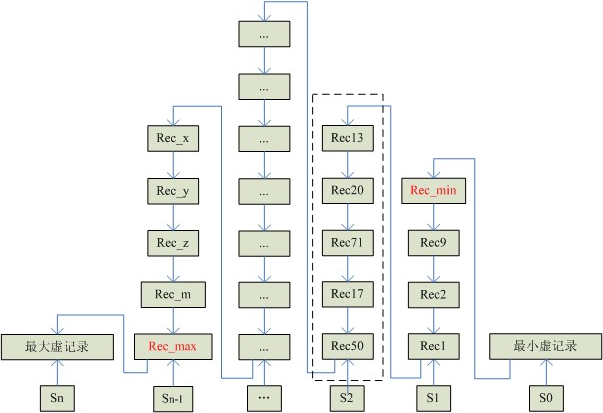
上面提到,页内的数据是一个很长的单向链表,那么实际查询的时候,若直接遍历,通常效率比较低
这里 MySQL 的查找方式就很像二分查找了 (注意:这里说的是页内的查找,页外的查找是靠的索引树)
首先页的 Slot 区会通过对页内记录的统计,计算出若干槽位来
每个槽位都会指向一条记录(是一条记录,不是一个区间的记录),通过这些槽位就能把页内的单向链表分成几段
查找数据时,通过偏移的方式去做二分查找,最终会找到一个槽位,然后再去遍历该槽位对应的这一段链表,即可
也就是说,MySQL 是借助 Slot 区实现了近似二分查找
索引实现
聚簇索引
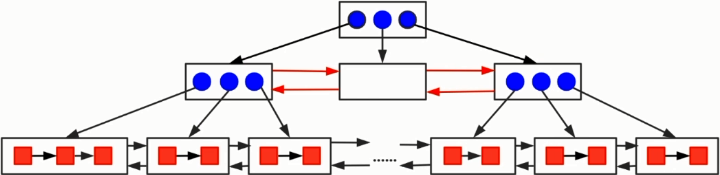
这是InnoDB聚簇索引的真实结构
根节点指向它的叶子节点(可以认为是一个page,里面有很多索引数据),叶子节点之间双向链接
最后的底层节点存的就是真正的主键 + Data,其页面之间也是双向链接
下面换一张更形象一点的图:
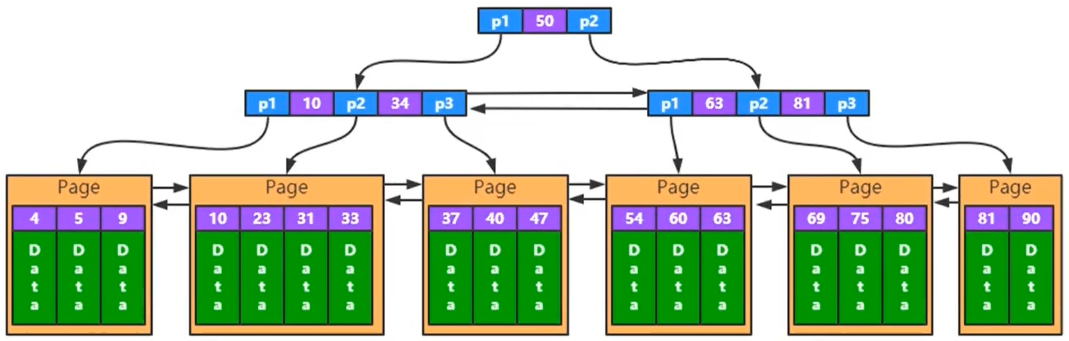
可以看到,聚簇索引的结构:通过树的方式,往下发散节点,最后到真正内存页:主键当key,Data存在它下面
比如主键为 10 的数据的存储结构:左边指针指向的都是小于 10 的数据页,右边指向大于等于 10 小于 34 的数据页
这就是聚簇的特点:数据与索引放在一起(找到索引也就找到了数据),且按照主键顺序存储(位于最底层的叶子节点)
所以,选择主键的时候,很显然递增主键是最合适的(顺序写入,效率高)
而随机主键,由于它的顺序可能忽大忽小,这会造成页内数据节点的分裂移动,使得写入性能下降,故不适合做主键
因此,实际工作中,更多的会采用类似雪花算法来生成趋势递增的数字,作为业务主键,其即参与业务,又当作主键
二级索引
指的是除主键索引以外的索引(也可以叫非聚簇索引),其最底层叶子节点存储的是主键值(不是实际的数据)
所以一次查询需要走两次索引,并且主键的大小会影响所有索引的大小(因为每一个非主键索引都会用到主键值)
下面是二级索引的结构示意图:
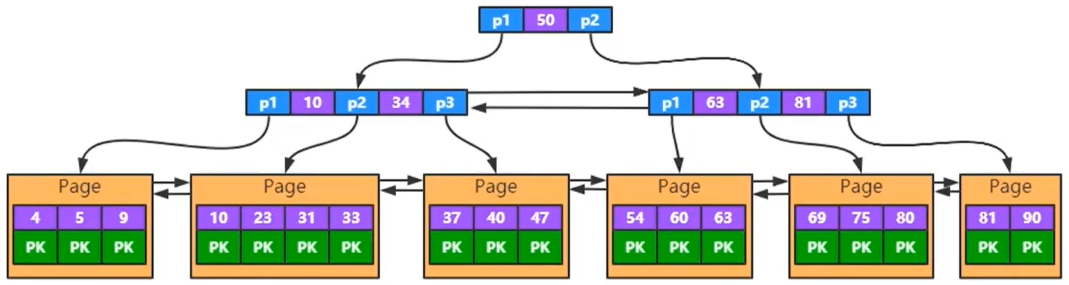
它跟聚簇不一样的地方是在 Data 域上:它的 Data 存的是主键的值
当我们用非主键索引去查询的时候,比如要找索引值等于 5 的数据,实际找到的是主键值,而非真正的数据
然后再拿主键值,回到主键索引(聚簇索引)上去找,最后找到了这条数据
而这个过程,也称为回表查询
联合索引
一个联合索引只创建一棵树,它由多个字段组成,排序时先按第一列排序,第一列相同就按第二列排(依此类推)
下面是它的结构示意图:
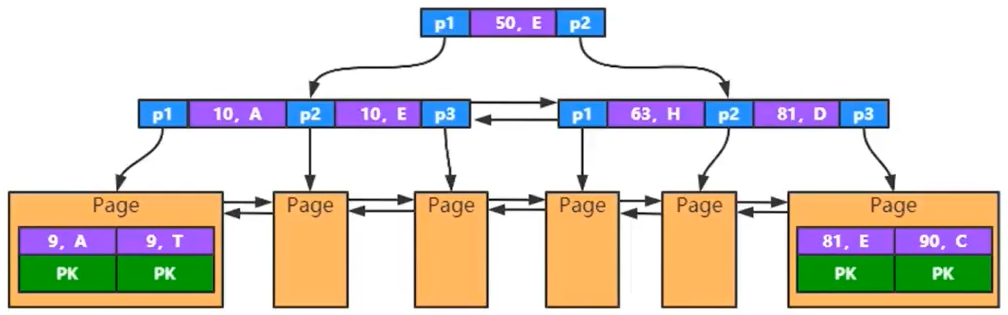
其实联合索引就是从一个 key 变成多个 key,然后再定义一个比较的规则,这样就构成了联合索引
也就是把索引的 “多个字段” 都放到索引 key 里面,比较的时候,就比较最左前缀(先比较第一列,再比较后面的列)
可以看到,联合索引还是一个二级索引,它最终拿到的还是主键值,还是要回表才能查到真正的数据
最左匹配原则
实际在查询时,它也是遵循最左匹配原则的,以联合索引顺序 (a,b,c) 为例,下面是几个常见场景:
- 如果不是按照最左开始查找,则无法使用索引
b=xx AND c=xx:由于排序比较时,是先按 a 条件比较的,现在没有 a 条件,所以就没办法命中索引了 - 不能跳过中间列
a=xx AND c=xx:能用上一部分索引,因为通过 a 能够查到一个范围,然后回表拿到实际数据后,再根据 c 筛选 - 某列使用范围查询,后面的列不能使用索引
a≥xx AND b=xx:先通过 a 查到一个范围的记录,接着 b 就用不了索引了,因为 a 范围内,b 数据几乎是无序的
a=xx AND b≥xx AND c=xx:这时可以用到 a 和 b,但用不到 c,因为 b 是一个范围
索引区分度
创建联合索引时,通常会把索引区分度高(即全局唯一或者像时间这种能够区分出一个范围的)的字段放在前面
而如果把区分度过低的(比如性别、年龄)放在前面
比如性别,那么查询时,正常来讲会先找到一半数量的主键值,然后再逐个回表查询,最后返回结果
而实际上这种情况下 mysql 会认为它区分度太低了,使得查询效率很低,因此 mysql 会自动走全表扫描
覆盖索引
比如一张表,有三个字段:主键、uid、phone,现在想通过 uid 来查 phone
正常的,会对 uid 建一个索引,由于是二级索引,所以会走回表查询,最后查到 phone
实际上,如果这种查询很多的话,那么就可以利用联合索引的覆盖索引的特性,拿 uid 和 phone 来建一个联合索引
查询时,通过 uid 就会找到联合索引的 key 以及它的主键值,但是由于 key 里面已经包含了我要找的 phone
那这时,mysql 就不会再回表了,直接就会返回 phone(避免了回表)
索引下推
mysql 服务端有一个 Server 层,在 Server 层下面还有一个 InnoDB 存储引擎层
下面以查询条件 WHERE a=xx AND b≥xx 为例
如果只对 a 建一个二级索引,那么查询时,引擎层会将回表后得到的一批数据,返回给 Server 层
Server 层再根据 b 过滤,最后得到最终结果
而索引下推则是:根据 b 来过滤的动作,也交给引擎层来做
具体做法就是拿 a 和 b 建一个联合索引,由于联合索引具有索引下推的特性,所以 b 条件也会通过 Server 层传给引擎层
引擎层在根据 a 回表得到一批数据后,就会拿 b 来过滤,然后返回给 Server 层
由于是在引擎层直接就处理了,所以效率就变高了
由于联合索引具有的这些特性,所以,实际中,联合索引的使用,要优于多列独立索引
还有一点,其实联合索引也间接的满足了查询和排序
外置索引
比如根据商品信息或商品描述里面的某个词来查询
这时就不能用数据库的模糊查询了,效率太低,可以借助 Elasticsearch 这类工具来建一个外置索引
说白了就是:发布完商品,就把商品描述信息同步到 ES,ES 自动建立一个根据关键字到商品 ID 的索引
拿关键字查询的时候,就先到 ES 查一下都命中了哪些商品 ID,然后再返回商品
索引失效
- 索引区分度过低或者条件超出索引范围
比如时间戳字段做索引,查询条件是 ts>0,这时就会全表扫描,因为条件超出范围了 - a=xx OR b=xx
结论:这种场景下,a 与 b 都要建索引
分析:如果 a 建了索引,b 没有索引,那么 a 走完索引查到数据后
发现后面还有 OR 的条件,就还要根据 b 来查一遍,但是 b 又没有索引,这时就会全表扫描
注意:如果 a 和 b 都建了索引,那就意味着这是两棵树,而一次查询怎么能走两棵树呢?
为了解决这个问题,MySQL-5.1开始,引入了 Index Merge 技术,支持对同一个表使用多个索引分别扫描
最后对两棵树的查询结果取并集(如果是 AND 查询条件,就取交集) - 隐式类型转换
比如数据库手机号,是 char(11) 类型的,实际传入的参数是整型的,这时就会发现类型不匹配,就走全表扫描了 - 索引列包含计算
比如查询条件为 WHERE name-20=30,解决办法就是 WHERE name=50(把 20 挪到后面,规避掉计算步骤)