ZooKeeper介绍
zk 是一个分布式的,开源的,分布式应用程序协调服务,是 Google 的 Chubby 的一个开源实现
zk 是一个分布式数据一致性的解决方案,其设计目的是为了减轻分布式应用程序所承担的协调任务
它致力于提供一个高性能、高可用、具有严格的顺序访问控制能力的分布式协调系统
它使用文件系统目录树作为数据模型,可以实现分布式锁、队列管理、命名服务、配置管理、集群管理等等
简而言之,它的角色是一个服务协调者
通俗的讲,zk 以一个集群的方式对外提供协调服务,集群内部所有节点都保存了一份完整数据
其中一个主节点用来做集群管理提供些数据服务,其他的从节点用来同步数据(从节点必须和主节点数据状态一致)
- zk 集群中的所有节点的数据状态通过 ZAB 协议保持一致
- zk 没用沿用 Master/Slave 概念,而是引入了 Leader、Follwer、Observer 三种角色
通过 leader 选举来选定一台 follwer 机器作为 leader 机器,leader 负责读和写,follwer 只负责读
因为用一个 leader 进行写的话,就能控制事务的顺序保证,这样才能在分布式场景中让数据达成一致变得简单
唯一区别是 observer 不参与 leader 选举过程及写操作过半成功策略,因此 observer 可在不影响写性能情况下提高集群性能
并且,zk 有如下特点:
- 最终一致性:client 无论连接到哪个 server,展示给它的都是同一个数据视图,这是 zk 最重要的性能
- 可靠性:如果 msg 被一台服务器接收,那么它将被所有的服务器接收
- 原子性:事务操作只能成功或者失败,没有中间状态(通过 ZAB 协议实现)
- 顺序性:客户端先发送的消息一定会被先处理,并且服务端先接收到的消息也一定会被先处理
- 实时性:保证一段时间内能拿到结果(不保证两个客户端能同时拿到最新,如需最新数据,读之前应调用 sync() 接口)
- 等待无关(wait-free):慢的或者失效的 client 不得干预到快速的 client 的请求,使得每个 client 都能有效的等待
另外,zk 底层主要有三个重要组件:
- znode 文件系统(数据存储系统)
- watch 监听系统
- ACL 系统(用来做权限控制的,用到的不多)
znode
它主要为分布式应用存储少量关键的核心状态数据(不能超过 1 MB,最好小于 1 KB)
它和 Linux 的文件系统很像,也是树状(这样就可以确定每个路径都是唯一的)
但与 Linux 的文件系统不同的是:Linux 有目录和文件的区别,而 zk 中统一叫做 znode
每个 znode 都有一个唯一的绝对路径标识(zk 中没有相对路径的概念),并且既能存储数据,也能创建子 znode
关于 znode 的分类
- 按照生命周期:
- 持久(persistent):断开连接不删除(默认情况)
- 短暂(ephemeral):断开连接自己删除
- 按照是否自带序列编号:
- 非SEQUENTIAL:不带自增序列编号(默认情况)
- SEQUENTIAL:带自增序列编号
| 节点类型 | 详解 |
|---|---|
| persistent_sequential | 比如 A 到 zk 上建立一个 znode 名为 /zk/conf,指定了这种类型的节点后 zk 会创建 /zk/conf0000000000 B 再去创建就是 /zk/conf0000000001,C 再去创建就是 /zk/conf0000000001 以后任意 client 来创建这个 znode 都会得到一个比当前 zk 命名空间最大 znode 编号 +1 的 znode 即任意一个 client 去创建 znode 都能保证得到的 znode 编号是递增且唯一的 |
| persistent | 客户端创建该节点后,除非主动 delete,否则该节点及存储的数据都不会主动消失 |
| ephemeral_sequential | 临时的编号自增的节点,但会随 session 消失而消失 |
| ephemeral | client 连接到 zk 时会建立一个 session 一旦 client 关闭了 zk 连接,服务器就会自动清除该 session 及其建立的 znode(不需要我们主动调 api) |
注意点:
- ephemeral 节点不能有子节点
- ephemeral 节点在删除时会有延迟
会话断开时,zk 会识别该会话创建的那些 znode,它就会原子广播,让所有服务器都删除这些 znode,这需要时间 - SEQUENTIAL 类型的不同节点都有各自的自增序列编号的管理,均由其父节点管理,不同父节点的序列编号是独立的
- 创建 znode 时设置顺序标识,znode 名称后会附加一个值(/zk/conf),顺序号是一个单调递增的计数器
- 自增的顺序号可以用于事件的全局排序,这样客户端可以通过顺序号推断事件顺序
- 客户端可以在 znode 上设置监听器
watch
客户端注册监听它关心的节点,当节点发生变化(数据改变、节点删除、子节点增加删除)时,zk 会通知客户端
监听器的工作机制,其实是在客户端会专门创建一个监听线程,在本机的一个端口上等待 zk 集群发送过来事件
| 四种类型的事件 | 描述 |
|---|---|
| NodeCreated | 创建节点时,触发该事件 |
| NodeDeleted | 删除节点时,触发该事件 |
| NodeDataChanged | 修改节点数据时,触发该事件 |
| NodeChildrenChanged | 当前节点下创建或删除子节点时,触发该事件(修改子节点的数据不触发该事件) |
zk 提供了以上四种事件类型
并提供了以下三种监听的API:
- zookeeper.exists()
- zookeeper.getData()
- zookeeper.getChildren()
以及触发监听的三种方法:
- zookeeper.create()
- zookeeper.delete()
- zookeeper.setData()
三者之间的关系,如下图所示:
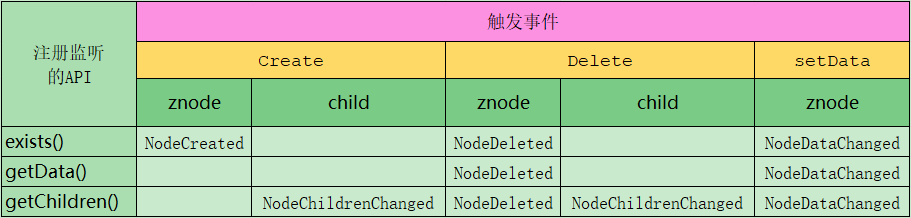
注意:注册的监听在事件响应(回调客户端)之后就失效了,所以要想连续监听,就要在回调 process() 方法中主动再去监听
zk 的 Watcher 机制主要包括客户端线程、客户端 WatcherManager、zk 服务器三部分
客户端在向 zk 服务器注册监听的同时,会将 Watcher 对象存储在客户端的 WatcherManager
当 zk 服务器触发 Watcher 事件后,会向客户端发送通知(WatchedEvent,包含三个信息:path、EnentType、connect)
客户端线程从 WatcherManager 中取出对应的 Watcher 对象来执行回调逻辑
脏读问题
zk 有一个小小的问题没有解决:如果事件响应特别快,那么中间会有部分事件被忽略
比如说某节点数据在很短时间内变化了 1000 次(频次非常高),但是客户端可能只会收到 900 次的通知
也就是说,这时 zk 系统的压力特别大,导致根本来不及发送每一次的事件消息给客户端
但事实上这种情况对于我们来说,影响几乎不大
ZooKeeperShell
| 常用命令 | 描述 |
|---|---|
| ls /zk | 查看路径为 /zk 的 znode 子节点列表 |
| create /zk “mydata” | 创建路径为 /zk 的 znode 节点,节点数据为 mydata |
| get /zk/mynode | 获取节点数据 |
| set /zk “mydata02” | 设置节点数据 |
| create -e /zk “mydata” | 创建临时节点 |
| create -s /zk “mydata” | 创建顺序节点 |
| create -e -s /zk “mydata” | 创建临时的顺序节点 |
| status /zk | 查看 znode 状态信息 |
| delete /zk | 只能删除没有子 znode 的 znode |
| rmr /zk | 级联删除 znode(不管里头有多少 znode,统统删除) |
| ls /zk watch | 对一个节点的子节点变化事件注册了监听 |
| get /zk watch | 对一个节点的数据内容变化事件注册了监听 |
ZooKeeper应用场景
目前企业中用的更多版本还是 3.4.X
发布订阅
发布订阅有两种模式:push 和 pull
在推模式中,服务端将所有数据更新发给订阅的客户端,而拉是由客户端主动发起请求获取最新数据(通常采用轮询)
zk 采用推拉结合,客户端向服务端注册自己需要关注的节点(即订阅),一旦该节点数据发生变更(即发布)
服务端向客户端发送 Watcher 事件通知(告诉你有数据更新),收到消息主动向服务端获取最新数据(自己去拉具体更新的内容)
这种模式主要用于配置信息获取同步
命名服务
只要成功创建了一个 znode(路径是绝对唯一的),也就意味着你命名了一个全局唯一的名称(如分布式全局唯一ID)
配置管理
将部署在多台机器上的应用程序的内部配置,都放到 zk 上的某个 znode 中,然后所有相关应用程序都监听该 znode
一旦配置发生变更,每个应用程序都会收到 zk 通知,然后通过 zk 获取新的配置信息
集群管理
所谓集群管理,无外乎以下两点:
-
是否有机器加入和退出
所有机器在 zk 中都有一个代表其存活状态的临时节点,而且他们都监听父节点的子节点变化消息
当有机器加入和退出时,那它对应的临时节点就会被增加或删除,由于都监听了父节点,于是就知道有兄弟机器上线或下线了 -
选举 Master
创建顺序编号的临时节点,每次按照一定策略(比如编号最小或 hash)选取指定编号的机器作为 master
或者指定固定的临时节点作为 master,slave 去监听它,一旦 master 不行了它就顶上(这种机制就是主从架构的 HA 机制)
其实只要实现数据唯一性就可以做到选举,关系型数据库也可以,但是性能不好,设计也复杂
分布式锁
-
排他锁(也叫独占锁或写锁,即对写加锁,保持独占)
由于 zk 有顺序性保证,两个客户端同时创建名称相同的临时节点时,一定会按先后顺序去执行,后来的则创建失败,即没拿到锁 -
时序锁(控制时序,即同一资源的请求按照先来后到的顺序执行)
每个客户端在同一个父节点下创建顺序编号的临时节点,而且监听父节点,并去父节点查询当前最小编号的是不是自己创建的
另外,关于分布式锁采用 zk(CP) 还是集群 redis(AP,单机 redis 才是 CP 的) 来实现,其实就是 CP 和 AP 的取舍问题
队列管理
两种类型的队列:
- FIFO队列:队列按照先进先出的方式,进行入列和出列操作(和分布式锁中的时序锁原理基本一致,入列有编号,出列按编号)
- 同步队列:当一个队列的成员都聚齐时,这个队列才可用(zk 才会给所有成员同时发消息),否则一直等待所有成员到达
实现方式:在约定节点下,创建临时节点,监听节点数量是否是我们期待的数量
负载均衡
借鉴分布式锁中的时序锁的实现机制,有点轮询的意思:即创建带编号的临时节点,编号是哪个,就调哪台机器